1. CLIP(Learning Transferable Visual Models From Natural Language Supervision)
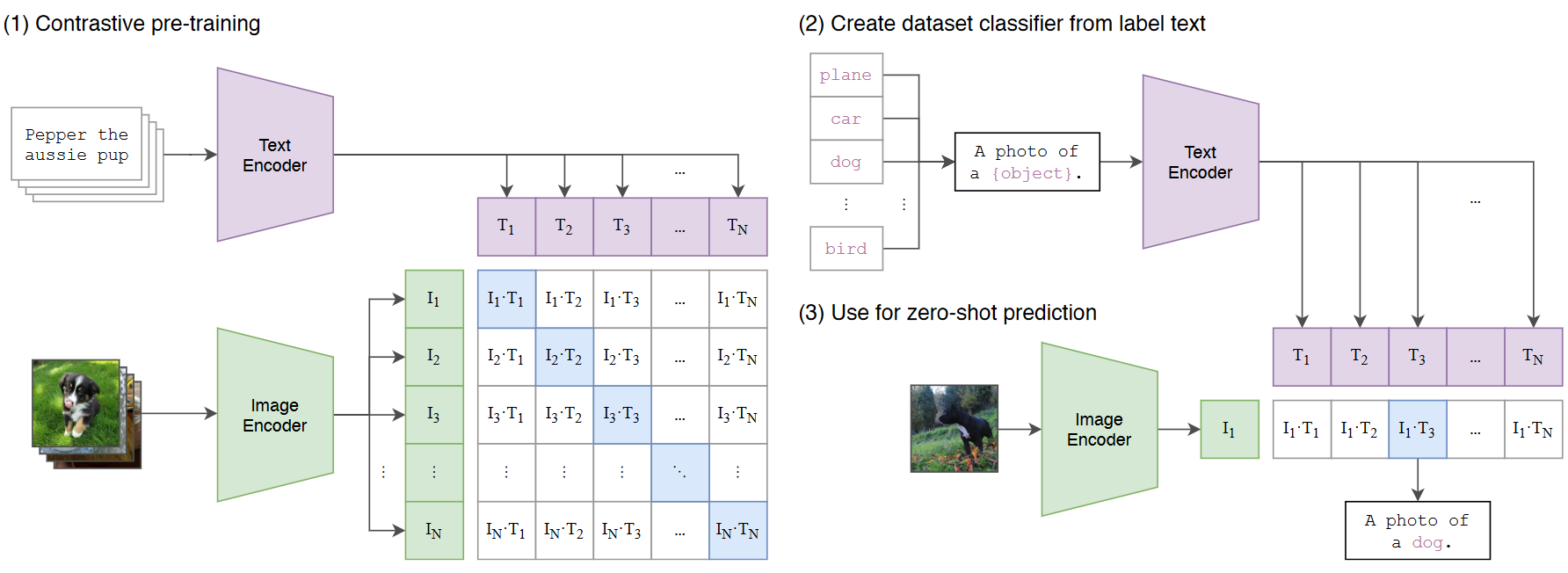
CLIP是OpenAI的一个非常经典的工作,从网上收集了4亿个图片文本对用于训练,最后进行zero-shot transfer到下游任务达到了非常好的效果,主要流程如下:
在训练阶段,文本会通过Text Encoder(Transformer)编码成一些文本Embedding向量,图像会通过Image Encoder(ResNet50或VIT)编码成一些图像Embedding向量,然后将文本Embedding和图像Embedding归一化后通过点积计算出一个相似度矩阵,这里值越接近于1代表文本Embedding和图像Embedding越相似,即这个文本和图像是配对的。我们的目标是让这个相似度矩阵对角线趋向于1,其他趋向于0(对角线代表图像和文本配对)。
测试zero-shot阶段,会将一张没见过的图片通过image Encoder得到图像embedding,然后将所有可能的类别,通过构造a photo of a {object}的文本标签,将所有类别填入object处,通过text encoder,得到所有类别对应的文本embedding,将文本embedding和图像embedding归一化后进行点积,选择点积最大的一个文本-图像对,该类别则为预测类别。
more >>