线性回归
线性回归是在假设特征满足线性关系,根据给定的训练数据训练一个线性模型,并用此模型进行预测。即使用一条函数曲线使其训练数据很好的拟合已知函数,并很好的预测未知数据。回归问题按照输入变量的个数可以分为一元回归和多元回归。
一、 单变量线性回归
线性回归是在假设特征满足线性关系,根据给定的训练数据训练一个线性模型,并用此模型进行预测。即使用一条函数曲线使其训练数据很好的拟合已知函数,并很好的预测未知数据。回归问题按照输入变量的个数可以分为一元回归和多元回归。
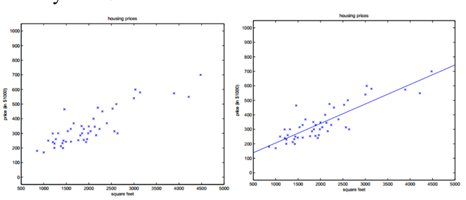
对于一元线性回归,函数用可以用一个公式来表示,即假设$x$和$h_{\theta}(x)$之间存在这样的关系:
$h_{\theta}(x)$即我们预测的数值,该值与实际数值之间的差异,即为误差:
由于求绝对值过于繁琐,我们将其视为误差平方和,并对齐求均值,即代价(损失)函数:
我们的目的就是使得预测值尽可能地接近实际值,即误差越小越好。即找到一组$(\theta_0,\theta_1)$,使得误差平方和最小。
Hypothesis:$h_{\theta}(x) = \theta_0 + \theta_1 x$
Parameters:$\theta_0,\theta_1$
Cost Function:$J(\theta_0,\theta_1) = \frac{1}{2m}\sum_{i=1}^{m}\left(h_{\theta}(x^{(i)}) - y^{(i)}\right)^{2}$
Goal:$\underset{\theta_{0}, \theta_{1}}{\operatorname{minimize}} J\left(\theta_{0}, \theta_{1}\right)$
二、多元线性回归
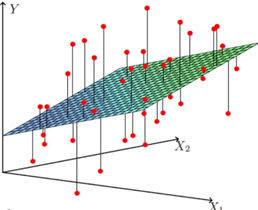
对于多元线性回归而言:
使用极大似然函数来解释最小二乘:
根据中心极限定理,误差$\varepsilon^{(i)}(1≤i≤n)$是独立同分布的,服从均值为0,方差为特定$\sigma^2$的高斯分布。
将式$(5)$带入式$(6)$中可得:
其似然函数:
高斯的对数似然与最小二乘
其中$m\cdot log\frac{1}{\sqrt{2\pi}\sigma}$为常数,则关于θ的代价函数为:
1 | temp=(X * theta - y)' * (X * theta - y); |
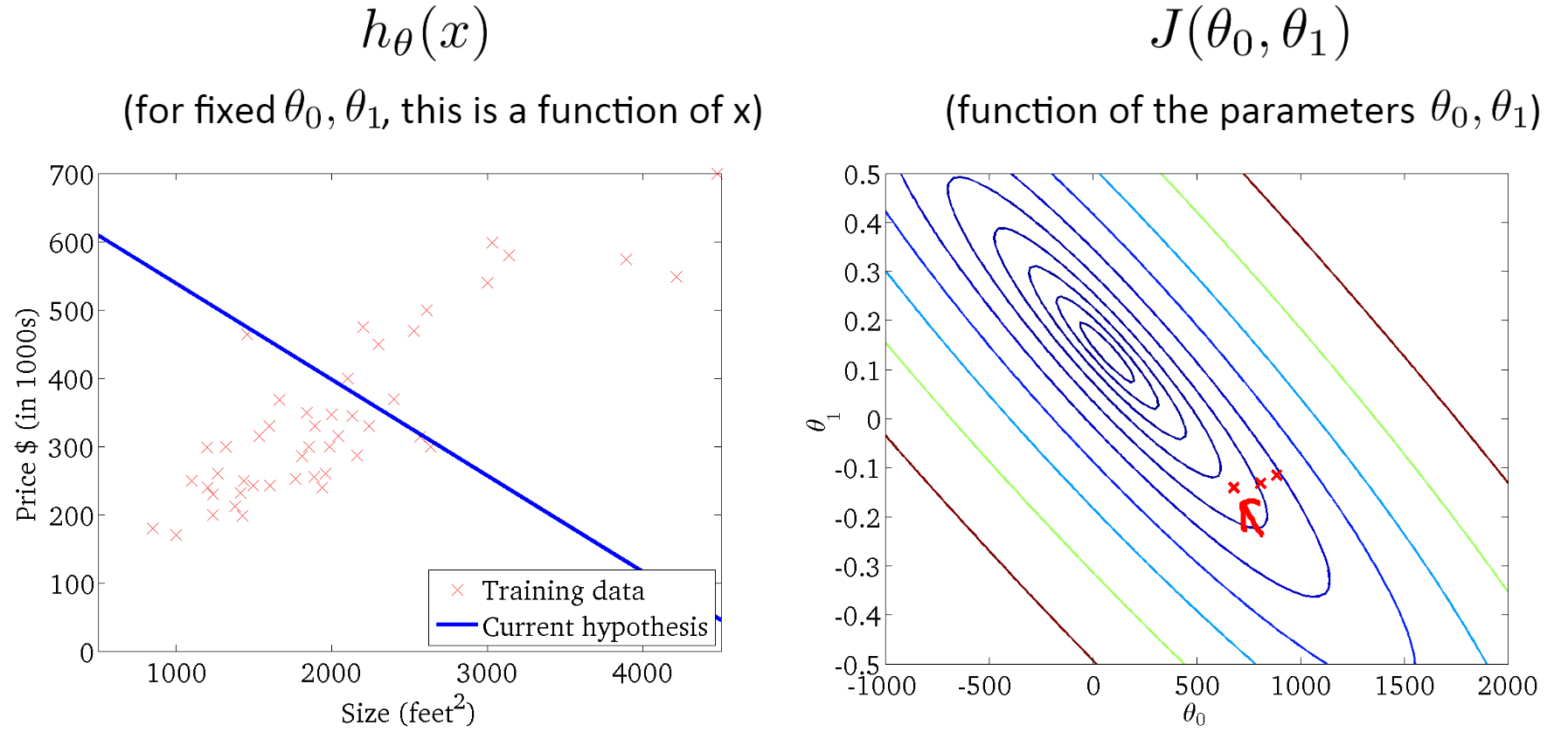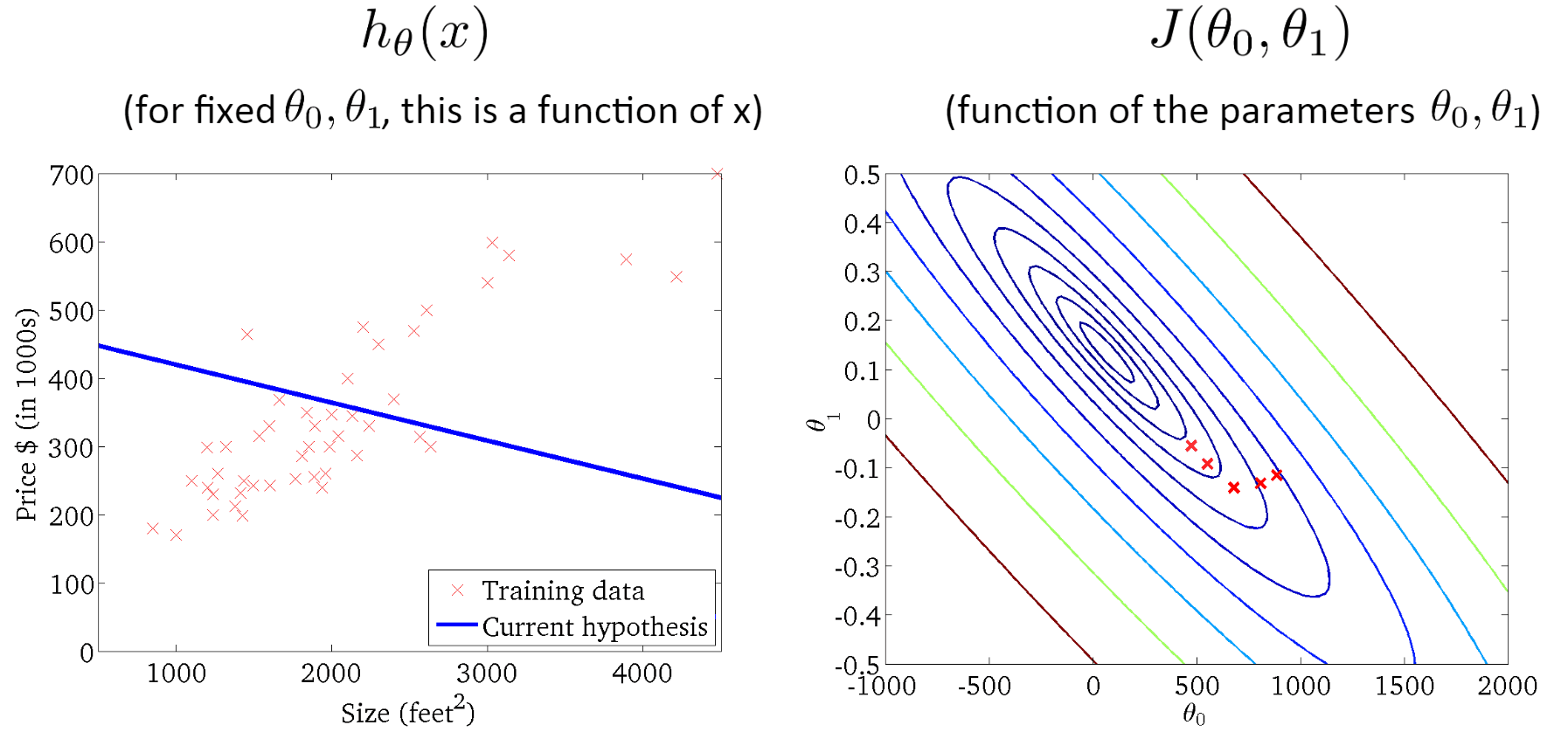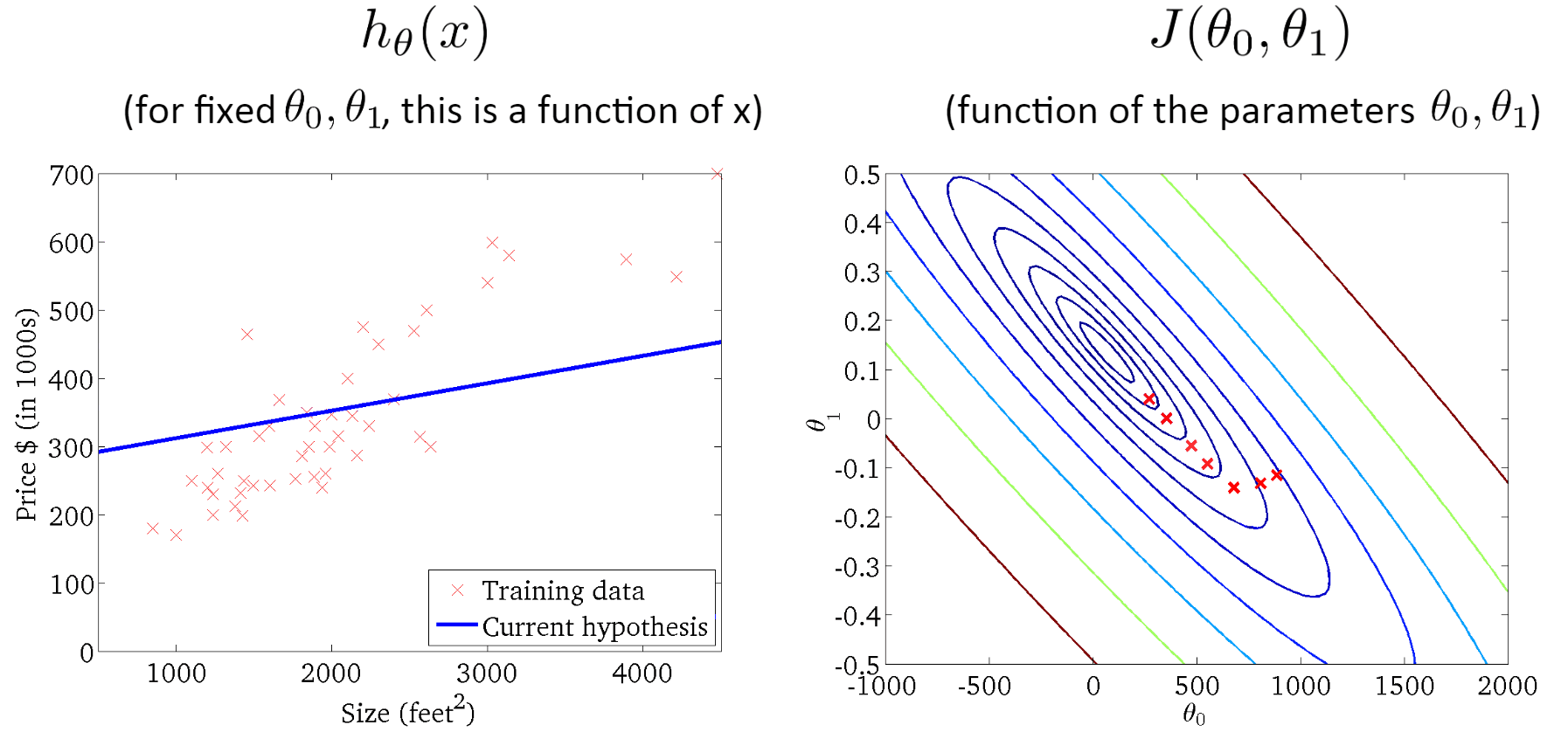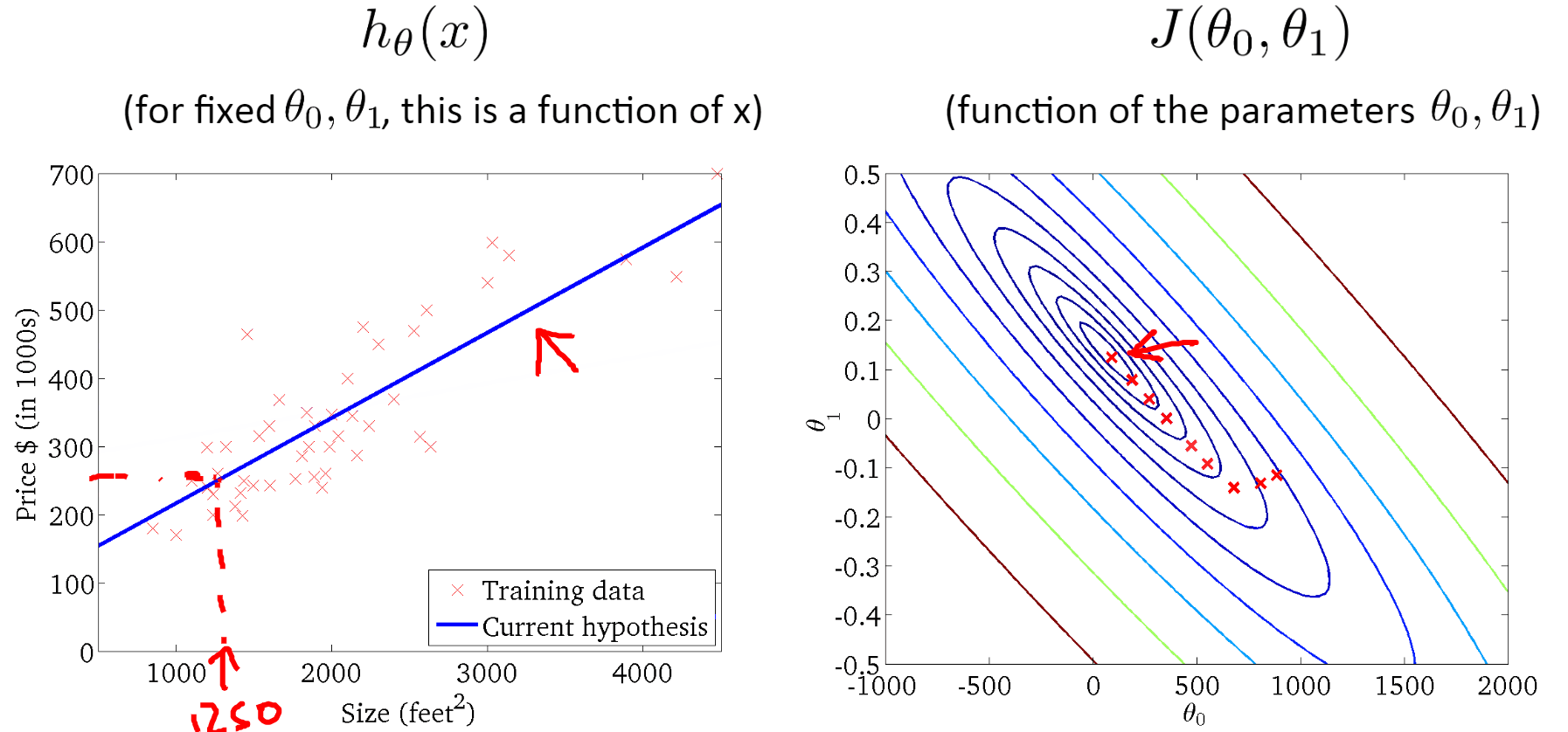
三、梯度下降算法
可以理解为一个人下山的过程,如果想要快速走下山,但是又不知道方向,怎么办呢?显然很容易想到的是一定往下山的方向走。但是选哪个方向呢?这就需要有冒险精神,每次选择最陡峭的方向,即山高度下降最快的地方,这样下山最快。
但是,又有一个问题来了,没有办法每次选择的都是最陡峭的地方。这就需要每次都选定一段距离,每走一段距离之后,就重新确定当前所在位置的高度下降最快的地方。这样,这个人每次下山的方向都可以近似看作是每个距离段内高度下降最快的地方。
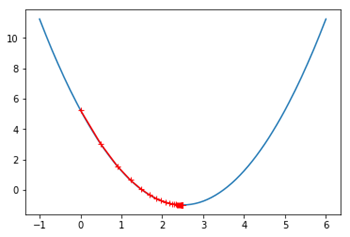
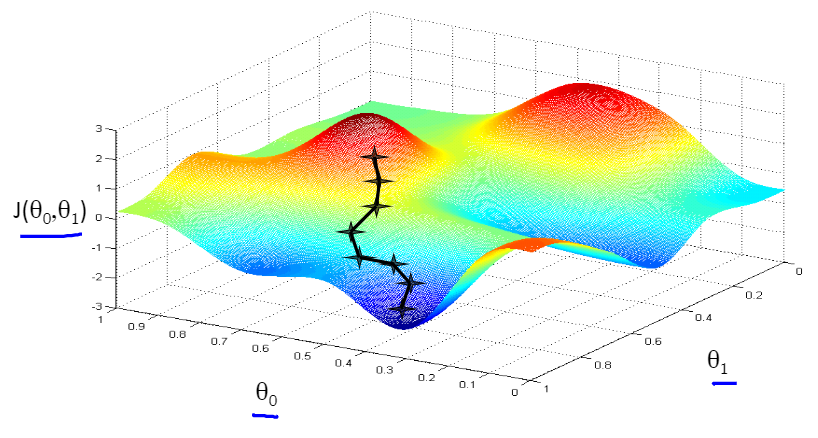
将下山的例子中每一段路的距离取名叫学习率(Learning Rate,也称步长,用α表示),把一次下山走一段距离叫做一次迭代。算法详细过程:
- 确定定参数的初始值,计算损失函数的偏导数。
- 将参数代入偏导数计算出梯度。若梯度为 0,结束;否则转到 3。
- 用步长乘以梯度,并对参数进行更新。
重复2-3,对于多元线性回归来说,拟合函数为:
损失函数为:
损失函数的偏导数为:
每次更新参数的操作为:
1 | for iter = 1:num_iters |
四、正规方程(最小二乘 )
得到多元线性回归的代价函数,可以通过求导和梯度下降来寻找最优的参数。
一元线性回归是对a、b求偏导,多元线性回归是对θ求偏导,即:
目标函数
对$\theta$求梯度:
矩阵(向量)求导法则
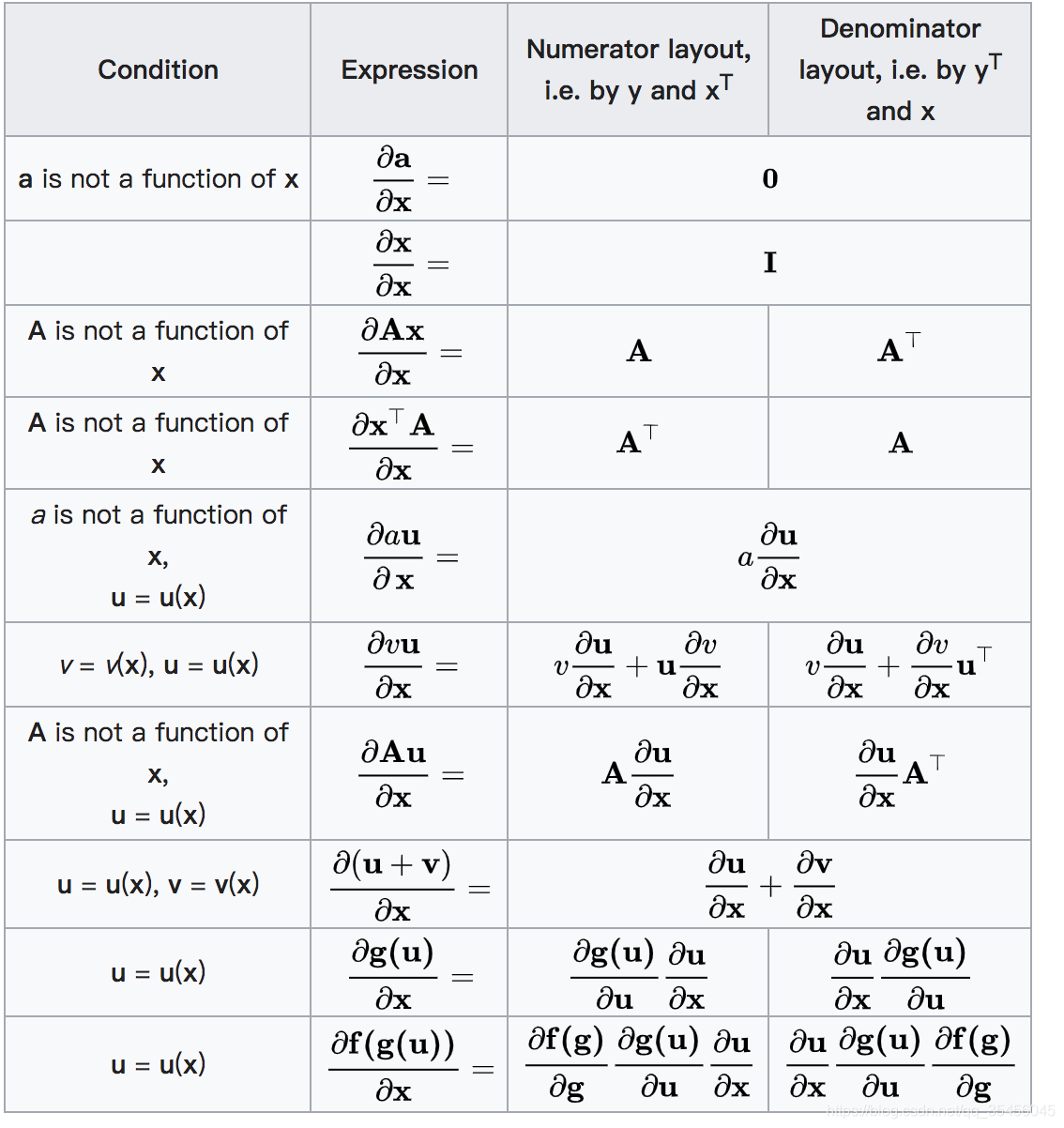
其中第一项:$ \frac{\partial}{\partial \theta} \theta^TX^TX\theta$,由矩阵求导法则:
将$X^TX$看作$A$,可得:
第二项:$\frac{\partial}{\partial \theta} \theta^TX^Ty$
矩阵求导法则:
将$X^Ty$看作$A$,可得:
第三项:$\frac{\partial}{\partial \theta} y^TX\theta$
矩阵求导法则:
将$y^TX$看作$A$,可得:
第四项:$\frac{\partial}{\partial \theta} y^Ty$
矩阵求导法则:
将$y^Ty$看作$A$,可得:
综上所述
当$\nabla_{\theta}J(\theta) = 0$时
如果$X^TX$不可逆,可能有两个原因:
- 列向量线性相关,即训练集中存在冗余特征,此时应该剔除掉多余特征;
- 特征过多,此时应该去掉影响较小的特征,或使用“正则化”;
方法选择
| 梯度下降法 | 正规方程法 | |
|---|---|---|
| 学习率$\alpha$ | 需要 | 不需要 |
| 特征归一化 | 需要 | 不需要 |
| 计算次数 | 需要迭代很多次 | 不需要迭代 |
| 特征数量 | 受特征数量影响较小,即使$n$很大也可以正常工作 | 如果$n$很大计算速度会很慢 |

