一、数据来源
1.1 指导教师提供的数据
共包含5张大尺寸(21184x21279)的卫星原图及其所对应同样大小的建筑、道路、水体和植被的标记图,我们不能直接把这些图像送入网络进行训练,因为内存承受不了,而且他们的尺寸也各不相同。因此,首先将他们做随机切割,即随机生成(x,y)坐标,然后抠出该坐标下256x256的小图,并做一些常见的数据增强操作,使得更适合训练我们的网络,最终获取到5000张256x256大小的训练数据,其中部分数据如下图所示。

链接:https://pan.baidu.com/s/1OqTrmWqR-05zMqNPZqmUnw 提取码:bvuq
1.2 Road and Building Detection Datasets开源数据
其中包括Massachusetts Roads Dataset(马萨诸塞州道路数据集)、Massachusetts Buildings Dataset(马萨诸塞州建筑数据集),共有1109张1500x1500大小的tiff格式的遥感原图及其中对应tif格式的标签图。我们共获取了建筑和道路各36张训练数据、14张验证数据,同上做数据随机分割并进行数据增强。最终生成1500张256x256大小的数据集。其中部分数据如下图所示。

Road and Building Detection Datasets 下载地址
一些处理后的数据
链接:https://pan.baidu.com/s/1NZ0rnpRpzZDIbtbB-LKMqg 提取码:hx7n
1.3 其他数据集(自我标注)
使用腾讯地图开源API获取到中北大学卫星图像,取得8张1024x768大小卫星遥感图像(仅供学习使用),同样对其进行随机裁剪。使用labelme图像标注工具对切割后的图像进行自我标注。由于其中道路、水体边界不明显,难以标注,因此只对建筑、植被进行了标注。最终共生成建筑、植被自我标注数据集各60张,其中部分数据如下图所示。

1.4 其他遥感分割数据集
开源数据集
- UC Merced Land-Use Data Set 总包含21类场景图像,每一类有100张,共2100张。
Gaofen Image Dataset [link] [arXiv] GID由两部分组成:大规模分类集( The large-scale classification set, ~55G)和精细土地覆盖分类集(The fine land-cover classification set, ~5G)。
- “华为云杯”2020人工智能创新应用大赛
- DeepGlobe卫星图像地表解析(道路提取、建筑物检测、地标分类)挑战赛
二、数据增强
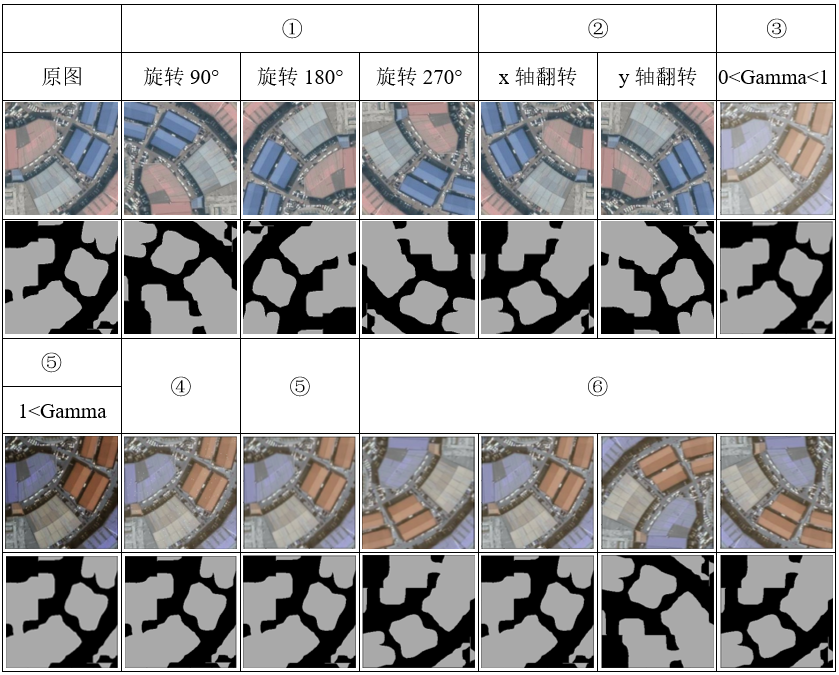
为了获得更多的数据,我们只要对现有的数据集进行微小的改变,比如翻转、移位、旋转等微小的改变,我们的网络会认为这是不同的图片。另外,数据增强可以使得卷积神经网络具有不变性,即能够对物体即使它放在不同的地方也能稳健的分类。综上,我们对数据集随机进行了以下处理:
- ① 原图和label图同时顺时针旋转:90度、180度、270度。
- ② 原图和label图同时沿x、y轴做镜像操作。
- ③ 使用Gamma变换(非线性映射)。
- ⑤ 原图做模糊(滤波)操作。
- ⑥ 原图增加噪声操作。
- ⑦ 随机以上数据处理。
三、语义分割网络
语义分割一直是个很活跃的研究课题,早期的分割算法主要是灰度分割、条件随机场(CRF)等一些较为传统的算法。近些年来,研究人员将深度学习运用到计算机视觉领域,利用深度网络技术的图像语义分割技术,突破了传统图像分割的瓶颈,构建了端到端的深度学习网络。从最初的Patch Classification方法到2014年Long等人提出FCN网络将传统的CNN网络中的全连接层全部替换成卷积层,从此DL/NN方法席卷了整个语义分割领域。
现如今,常用的语义分割方法中主要有:基于条件随机场(CRF)的方法如DeepLab,CRFasRNN;FCN架构及其解码级的变体SegNet,Bayesan SegNet;多尺度融合的方法;循环神经网络的方法等。深度网络在语义级的图像分割上取得了很多富有成效的结果,但仍然有很多问题尚待突破。
3.1 SegNet网络
SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation(一种用于图像分割的深度卷积编码器/解码器架构),也称为语义像素分割。该网络由一个编码器网络,一个相应的解码器网络,以及一个像素分类层组成。对输入图像进行低维编码,然后在解码器中利用方向不变性能力恢复图像。SegNet的创新之处在于解码器对较低分辨率的特征图进行上采样的方式。SegNet网络结构如下图所示。
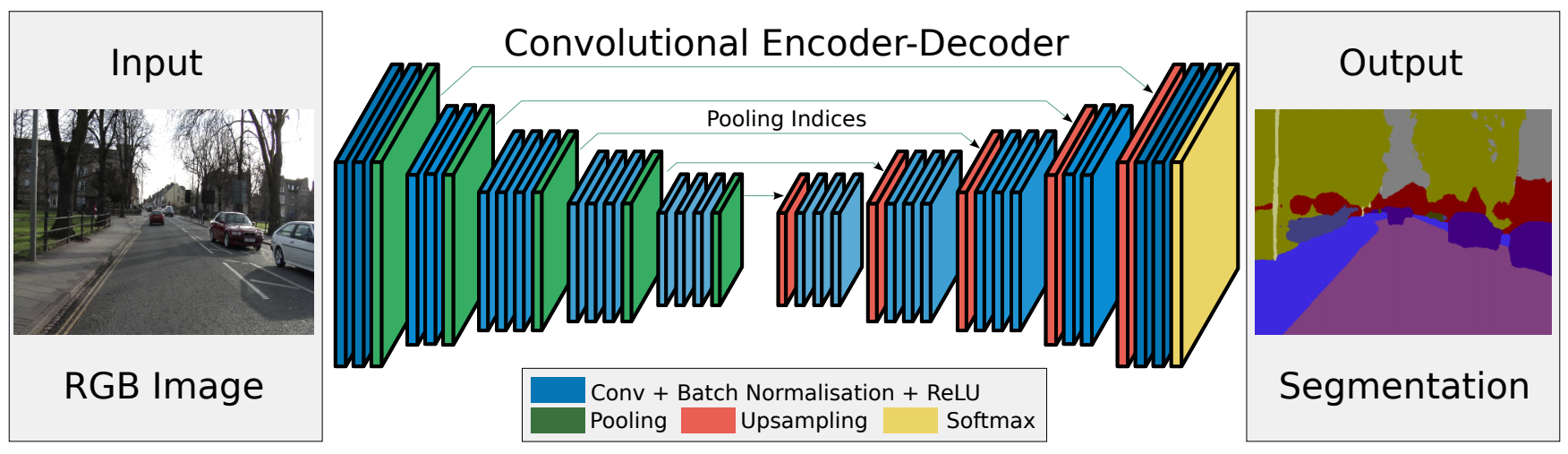
左边通过卷积提取特征,并通过pooling 增大感受野,同时图片缩小,该过程成为Encoder。右边是反卷积与upsampling,通过反卷积使得图像分类后特征得以重现,upsampling还原到图像原始尺寸,该过程称为Decoder。每个编码器层都对应一个解码器层,最终解码器的输出被送入soft-max分类器以独立的为每个像素产生类概率。编码器/解码器体系结构如下图所示。
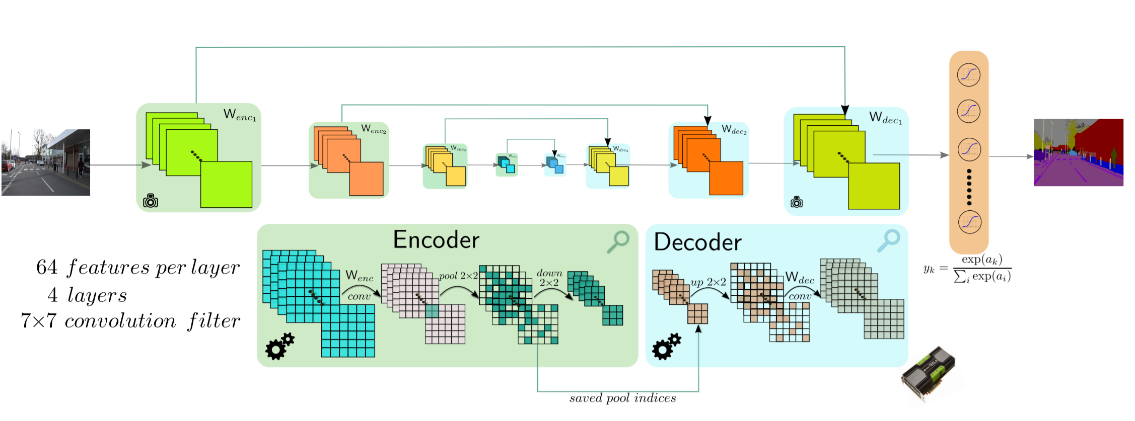
3.1.1 编码器网络结构
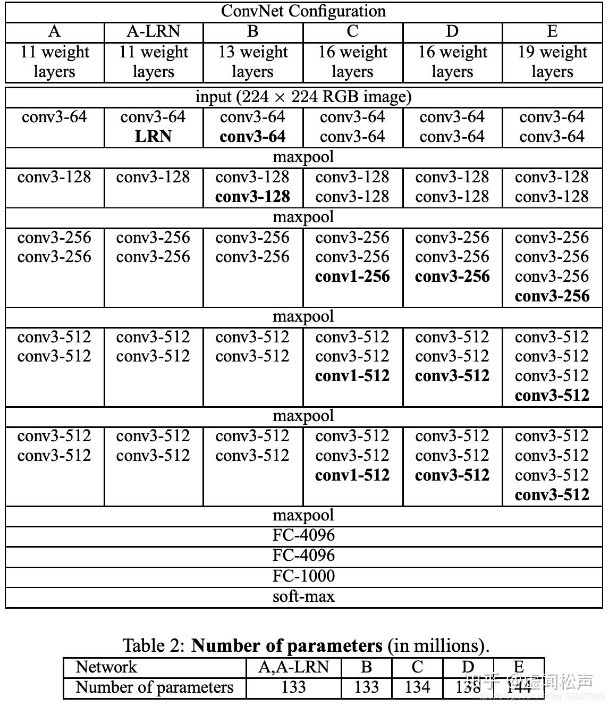
Encoder(编码器)网络的架构与VGG16网络中的前13层卷积层拓扑结构相同,并且移除了VGG16的全连接层(FC),在最深的编码器输出端保留分辨率更高的特征图。与其他架构相比,显著地减少了SegNet编码器网络中的参数数据量,使得该网络比其他架构更小、更容易训练。下图为Vgg的网络结构图,其中D列即为Vgg16的网络结构。
编码器网络中的每个编码器执行与卷积核的卷积(Convolution),以产生一组特征映射,然后进行批量标准化(Batch Normalisation),应用单元非线性激活函数(ReLU) max(0,x)。 随后,使用2×2大小、2步幅的窗口(非重叠窗口)执行最大池化。该过程使用的卷积为same卷积,即卷积后不改变图片大小。
3.1.2 解码器网络结构
Decoder(解码器)网络的作用是将低分辨率的编码器特征映射到,以便按像素分类。如下图所示,Polling之后,每个filter会丢失3个权重,这些权重是无法复原的,但是在SegNet中的Pooling比其他Pooling多了一个index功能(该文章亮点之一),也就是每次Pooling,都会保存通过max选出的权值在2x2 filter中的相对位置。
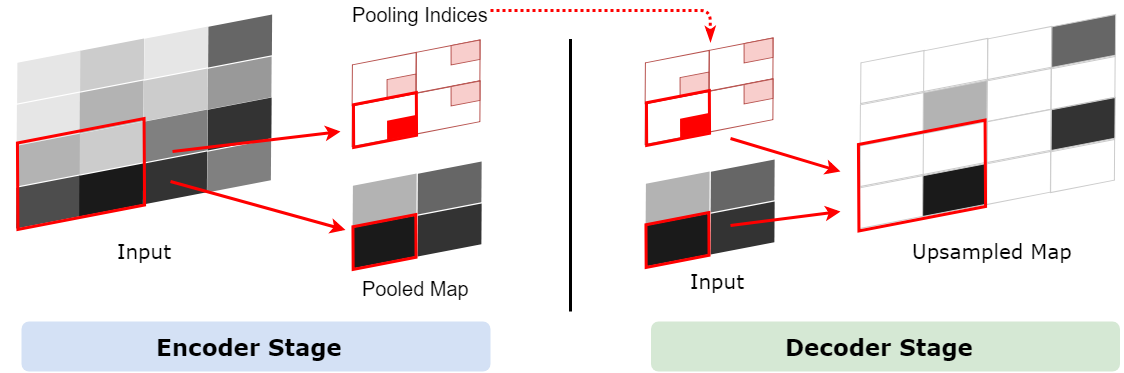
在Decoder过程中,使用保存的相对位置(max-pooling indices)来对其输入特征图进行上采样。从右边的Upsampling层中可以得知,2x2的输入变为4x4的输出,但是除了被记住位置的polling indices,其他位置的权值均为0。因此,SegNet随后使用反卷积来填充缺失的内容。
该过程同样使用same卷积,不过卷积的作用是为Upsampling变大的图像丰富信息,使得在pooling过程丢失的信息可以通过学习在Decoder得到。如下图所示。
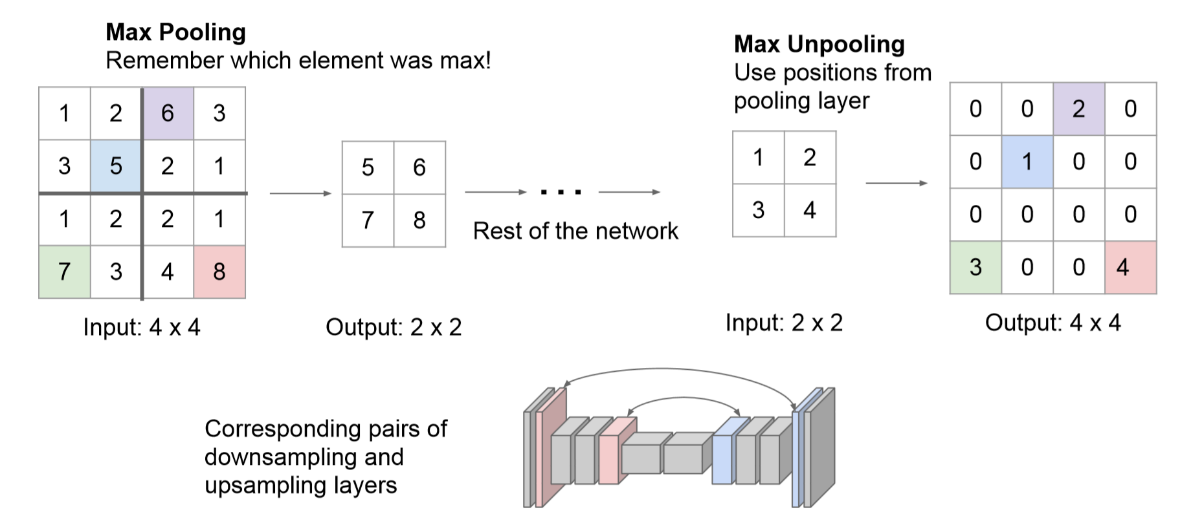
对于上图中蓝色的5来说,5在左上角的2x2 filter中的位置为(1,1)(index从0开始),绿色的7的index为(1,0)。在Max Unpooling过程中,对于1来说直接恢复到5的位置,其他位置同上。同时,从网络框架图可以看到绿色的Pooling层与红色的Upsampling层通过pool indices相连,实际上是pooling后的indices输出到对应的Upsampling层(因为网络是对称的,所以第1次的pooling对应最后1次的upsamping,如此类推)。
在解码的过程中重用最大池化索引有几个实际的优势:(i)改进了边界划分。(ii)减少了实现端到端训练的参数数量。(iii)这种upsampling模式可以结合到任何编码-解码网络中(FCN、CRFasRNN)。
1 | class SegNet(nn.Module): |
由于我们训练的网络输入大小是256x256,因此,对于单张256x256大小的测试图片,可以直接传入我们的网络进行预测。期间会返回一张1x2(类别数)x256x256大小的张量。计算通道维度上最大值对应的下标即为当前像素对应的类别标签,然后使用调色板进行调色即可。
3.2 Bayesian SegNet
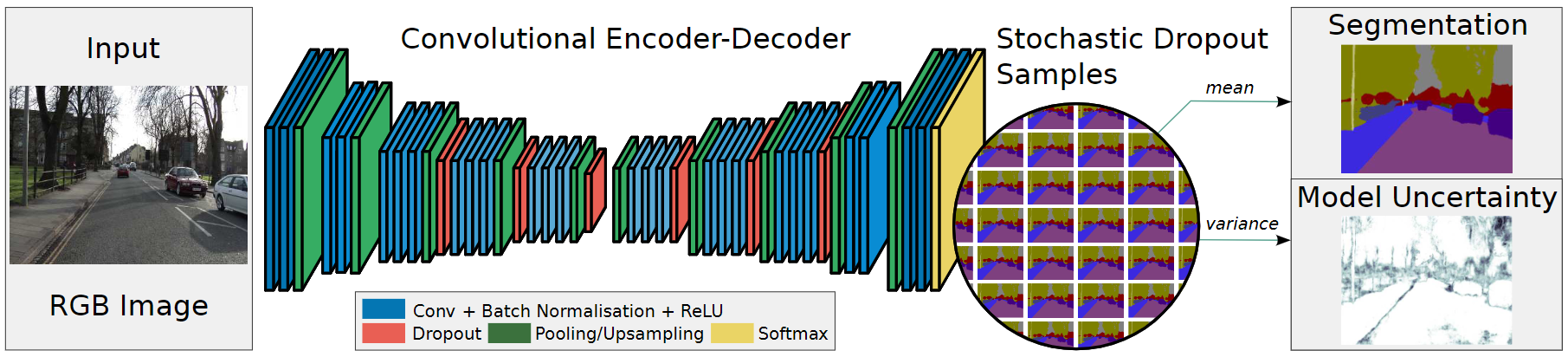
从网络变化的角度看,Bayesian SegNet只是在卷积层中多加了一个DropOut层。最右边的两个图Segmentation与Model Uncertainty,就是像素点语义分割输出与其不确定度(颜色越深代表不确定性越大,即置信度越低)。
在Bayesian SegNet中通过DropOut层实现多次采样,多次采样的样本值为最后输出,方差为其不确定度,方差越大不确定度越大,如上图所示,mean为图像语义分割结果,var为不确定大小。
3.3 Full convolutional networks(FCN)
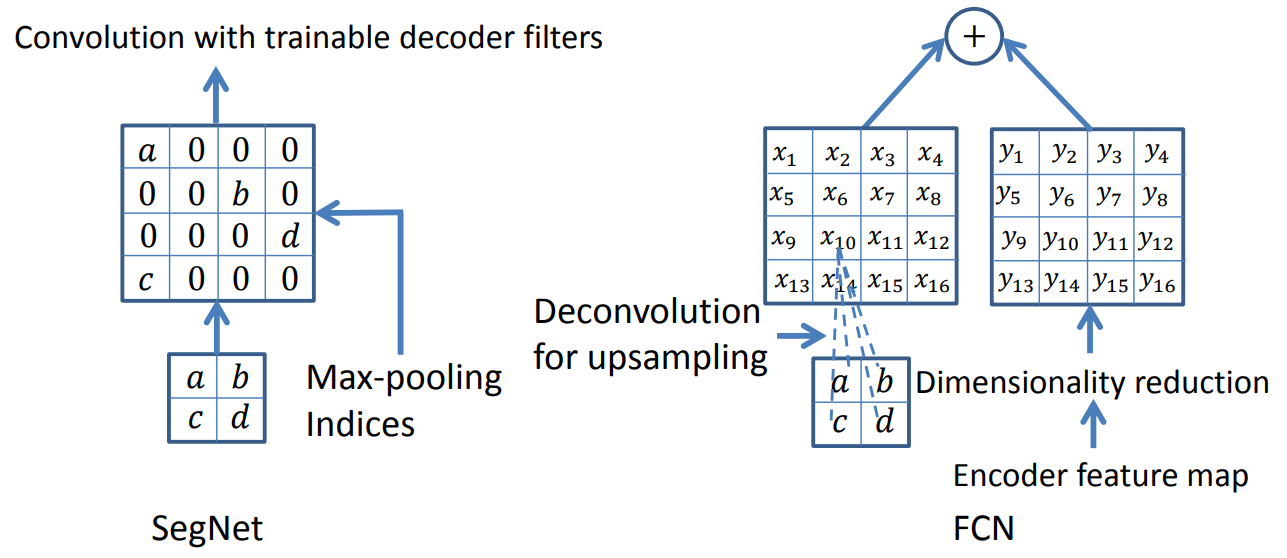
左图是SegNet(SegNet-Basic同)使用的解码技术,其中上采样步骤不涉及学习,上采样的映射与解码器的卷积核进行卷积,加密其稀疏输入。
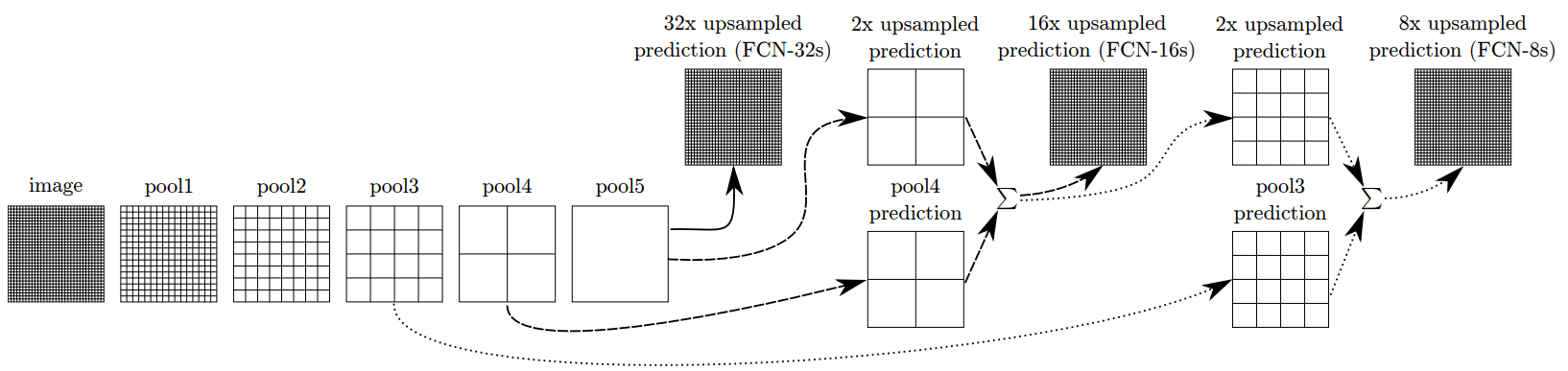
右图是FCN使用的解码技术,FCN模型的重要设计在于如何对编码器的特征图进行降维。在该网络的解码器中,通过使用固定的或可训练的多通道的逆卷积来执行上采样。我们将内核大小设置为8×8.这种上采样方式也被称为反卷积。相比之下,SegNet中解码器使用的多通道卷积是在上采样之后执行的,这使得特征图变得更密集。FCN的上采样要素图有K个通道,然后按元素将其添加到相应的编码器特征图中,以产生解码器特征图。其中32、16、8倍上采样的FCN架构如下图所示。
1 | import torch.nn as nn |
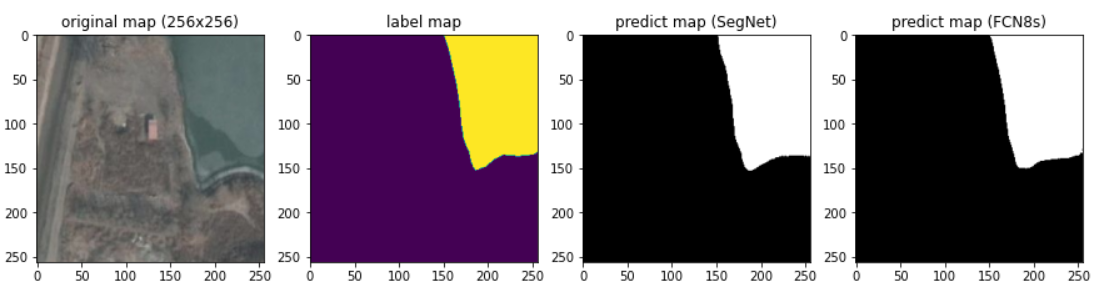
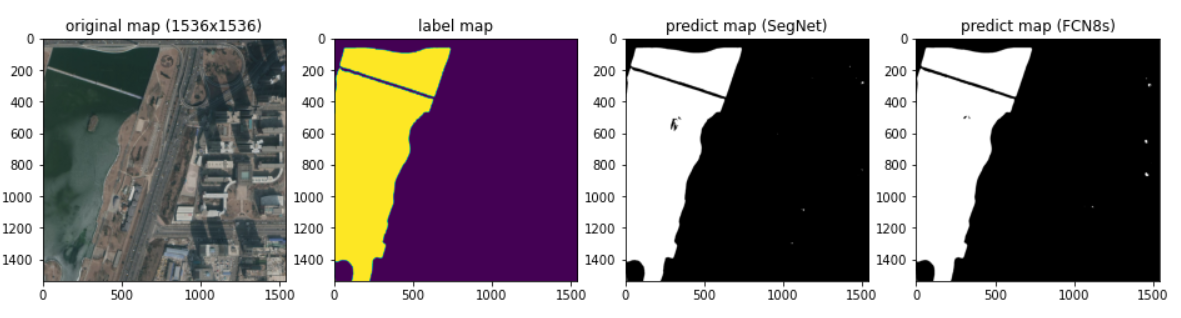
3.4 效果对比

3.5 语义分割评估指标
Mean Intersection over Union(MIoU,均交并比):为语义分割的标准度量。其计算两个集合的交并比,在语义分割的问题中,这两个集合为真实值(ground truth)和预测值(predicted segmentation)。计算公式如下:
其中i表示真实值,j表示预测值 ,pij表示将i预测为j。
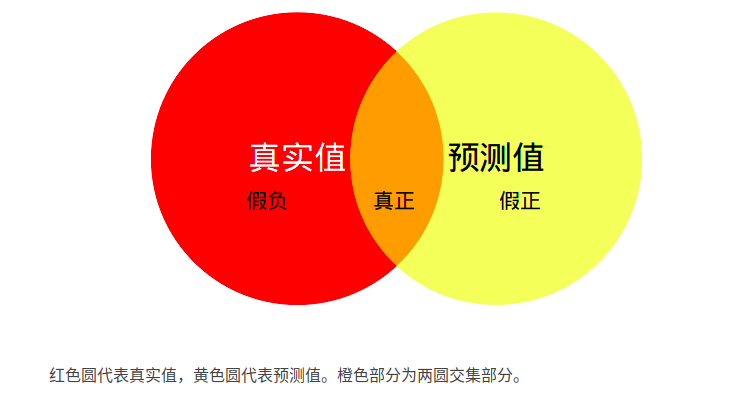
如上图5.1所示,MIoU即为计算两圆交集(橙色部分)与两圆并集(红色+橙色+黄色)之间的比例,理想情况下两圆重合,比例为1。由于使用的是二分类,因此不需要再计算混淆矩阵了。


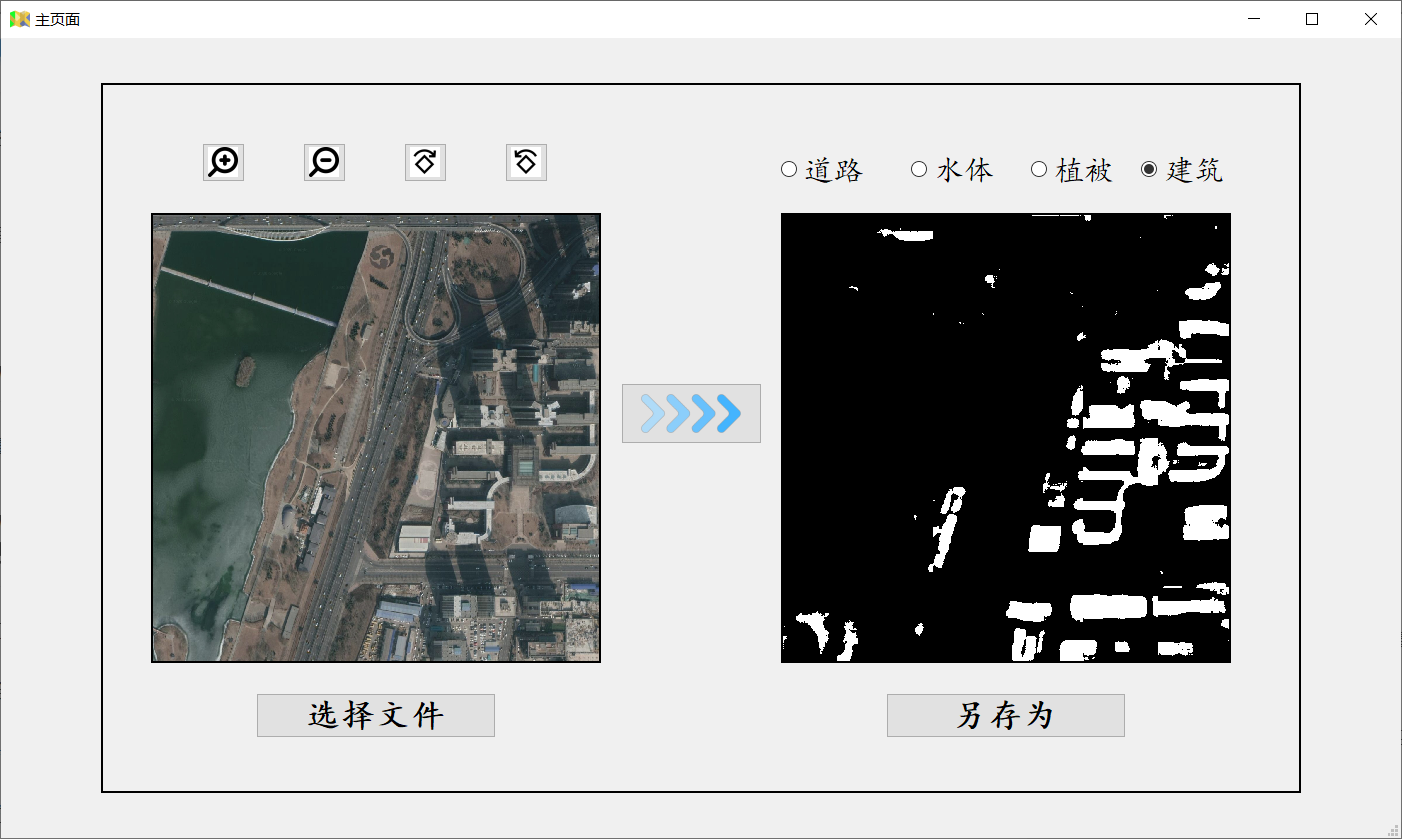
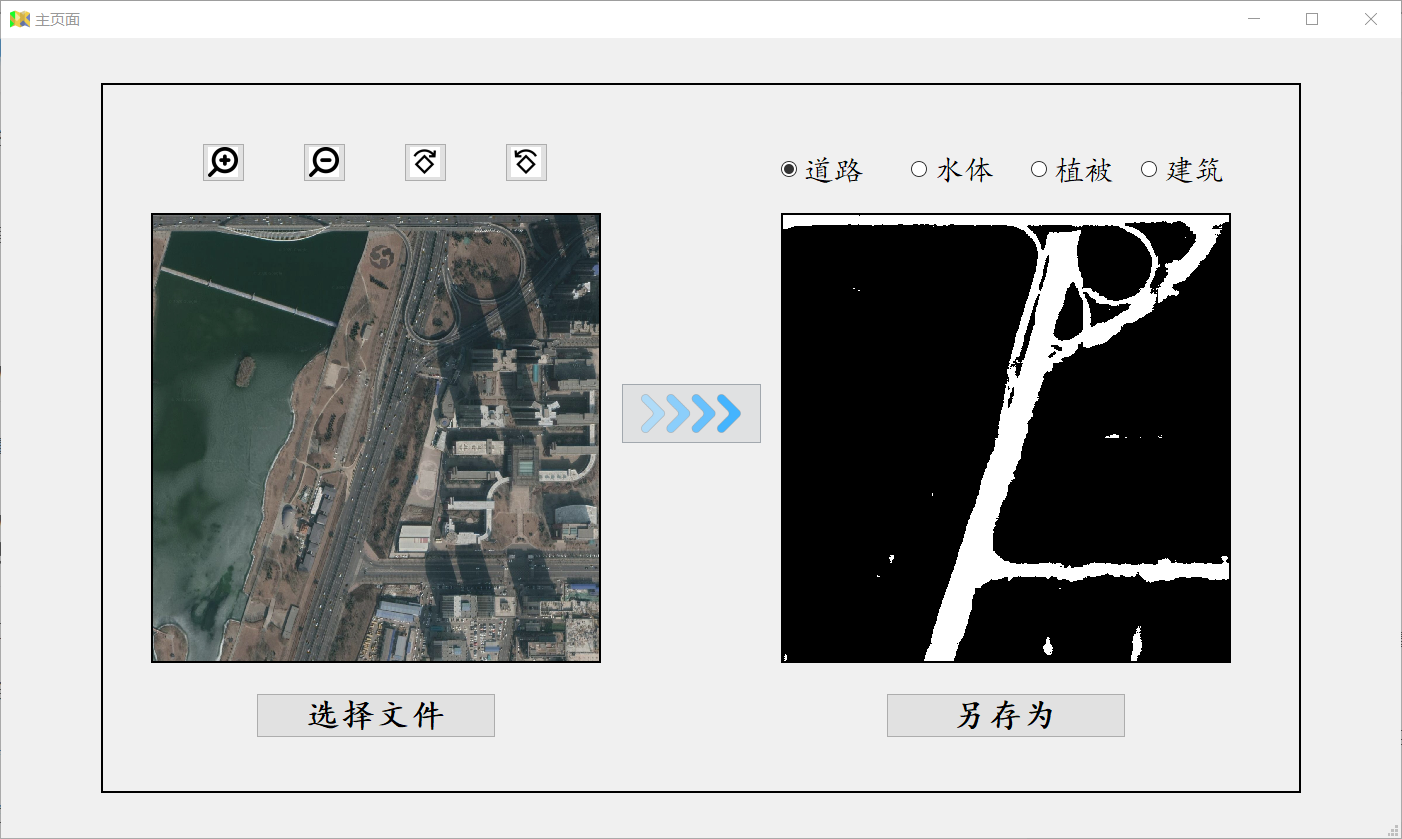
四、软件界面
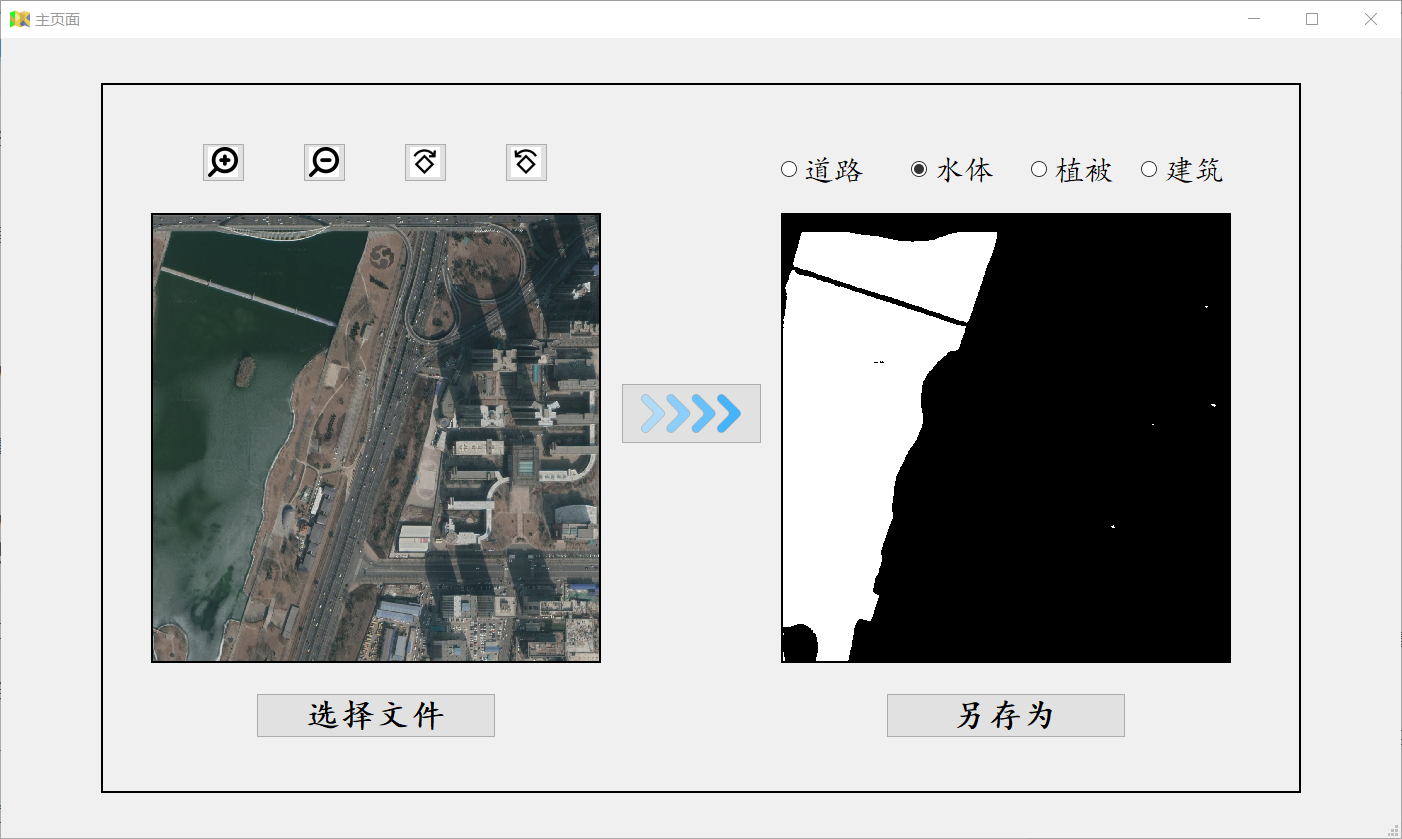
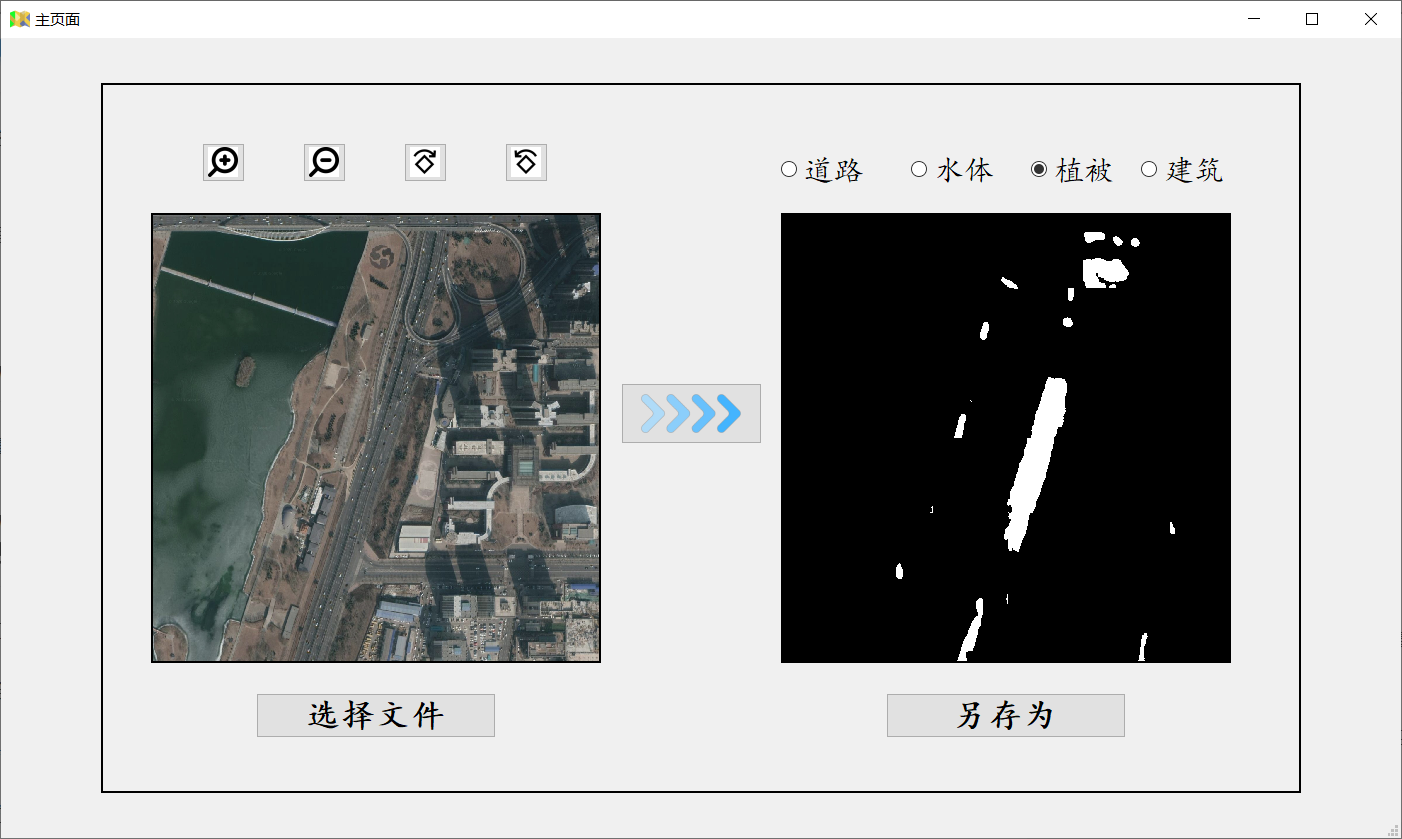
Reference
- SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation. [arXiv]
- Bayesian SegNet: Model Uncertainty in Deep Convolutional Encoder-Decoder Architectures for Scene Understanding. [arXiv]
- Fully Convolutional Networks for Semantic Segmentation. [arXiv]
- U-Net: Convolutional Networks for Biomedical Image Segmentation. [arXiv]
- DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. [arXiv]
- Foreground-Aware Relation Network for Geospatial Object Segmentation in High Spatial Resolution Remote Sensing Imagery. [arXiv]

