1. CLIP(Learning Transferable Visual Models From Natural Language Supervision)
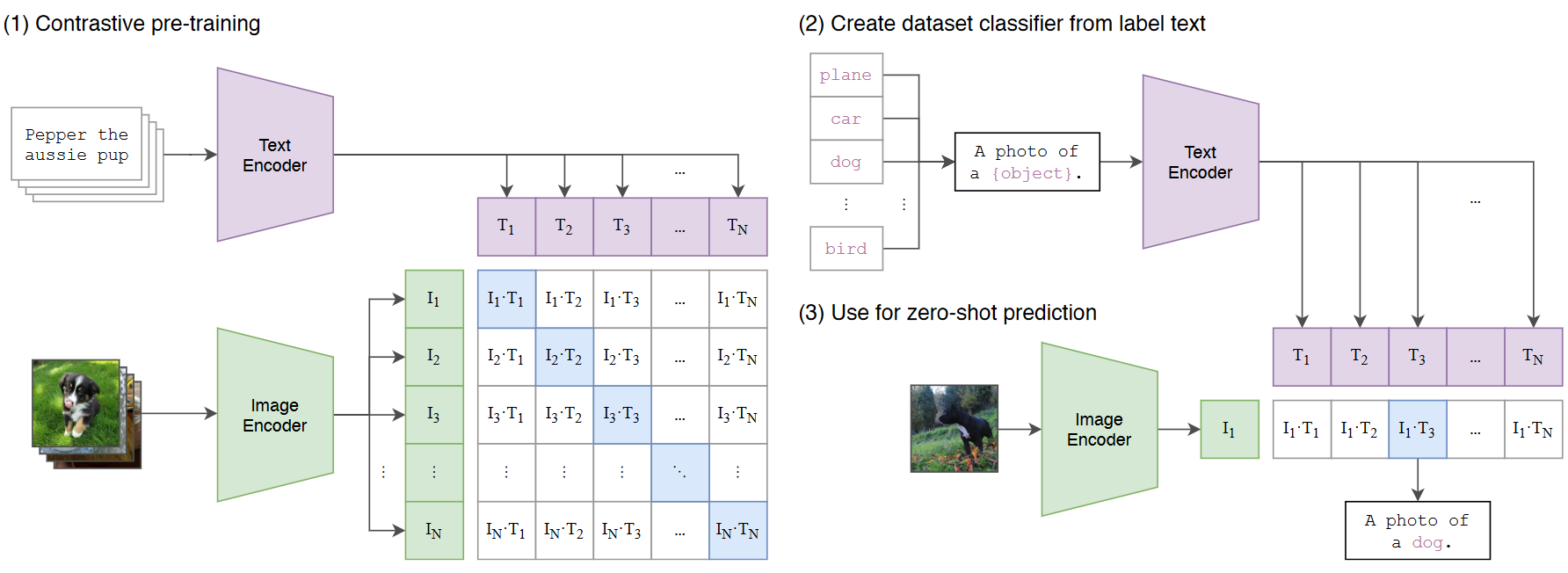
CLIP是OpenAI的一个非常经典的工作,从网上收集了4亿个图片文本对用于训练,最后进行zero-shot transfer到下游任务达到了非常好的效果,主要流程如下:
在训练阶段,文本会通过Text Encoder(Transformer)编码成一些文本Embedding向量,图像会通过Image Encoder(ResNet50或VIT)编码成一些图像Embedding向量,然后将文本Embedding和图像Embedding归一化后通过点积计算出一个相似度矩阵,这里值越接近于1代表文本Embedding和图像Embedding越相似,即这个文本和图像是配对的。我们的目标是让这个相似度矩阵对角线趋向于1,其他趋向于0(对角线代表图像和文本配对)。
测试zero-shot阶段,会将一张没见过的图片通过image Encoder得到图像embedding,然后将所有可能的类别,通过构造a photo of a {object}的文本标签,将所有类别填入object处,通过text encoder,得到所有类别对应的文本embedding,将文本embedding和图像embedding归一化后进行点积,选择点积最大的一个文本-图像对,该类别则为预测类别。
CoOp: Learning to Prompt for Vision-Language Models

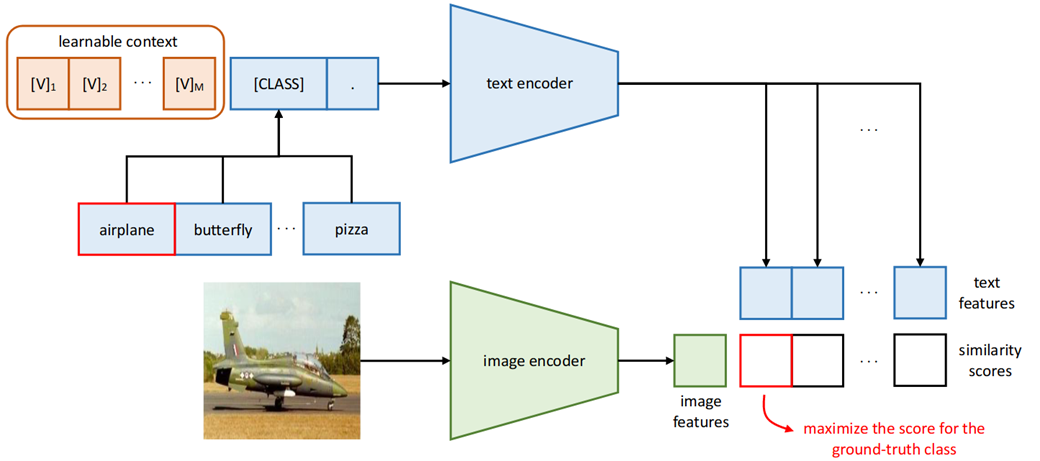
CoOp的motivation如上图所示:CLIP是固定prompt:a photo of a [class],但是不同prompt的影响影响很大,比如从图a可以看出,少了一个a,acc直接低了6个点。每次根据人工设计prompt太麻烦,设计的还不一定好,那怎么办呢?熟悉nlp的prompt的小伙伴应该脱口而出了,应该像Prefix Tuning一样,学一个连续的prompt不就完事了吗?CoOp就是这么做的。
CoOp从原来a photo fo a [class]转换成$[v]_1[v]_2[v]_3…[v]_M[CLASS]$这样可学习的连续的prompt,这样就不需要人工去设计prompt了。这里的prompt分为unified和class-specific两种,unified context即对所有类别都是学一组一样的prompt参数,class-specific context指的是对每一个类别学一个单独的prompt 参数,事实证明后者对一些细粒度的任务效果比较好。(看到这里的小伙伴可能有一个疑惑,还有instance-specific context这种更细粒度的可能,为啥这里没提呢?因为当时作者没想好怎么设计,想好之后又写了一篇CoCoOp)另外这里prompt里的[CLASS]不一定要放最后,也可以放句中,那这样学习明显更加灵活。
在实验这有一个有意思的发现:nlp领域有一篇叫OptiPrompt的文献,提出连续的prompt不一定要随机初始化,可以用人工设计的prompt的embedding初始化来引入专家经验,CoOp做实验发现就算prompt参数是随机初始化的也能到达一样的效果。
CoCoOp: Conditional Prompt Learning for Vision-Language Models

CoCoOp的motivation如上图所示:作者发现他们之前提的CoOp在训练过类别的数据集上表现的很好,但是面对新的类别,能力却很差,从80的acc降到65,而原版的CLIP却保持了还不错的泛化能力,引起了作者思考,作者认为这是因为CoOp在下游任务上训练时容易overfit base classes上。我认为一这个本质原因一方面因为用的prompt是unified或者class-specific,而不是instance-specific context,另一方面我认为用unified也可以,但是要有足够的数据学到真正的unified的特征。
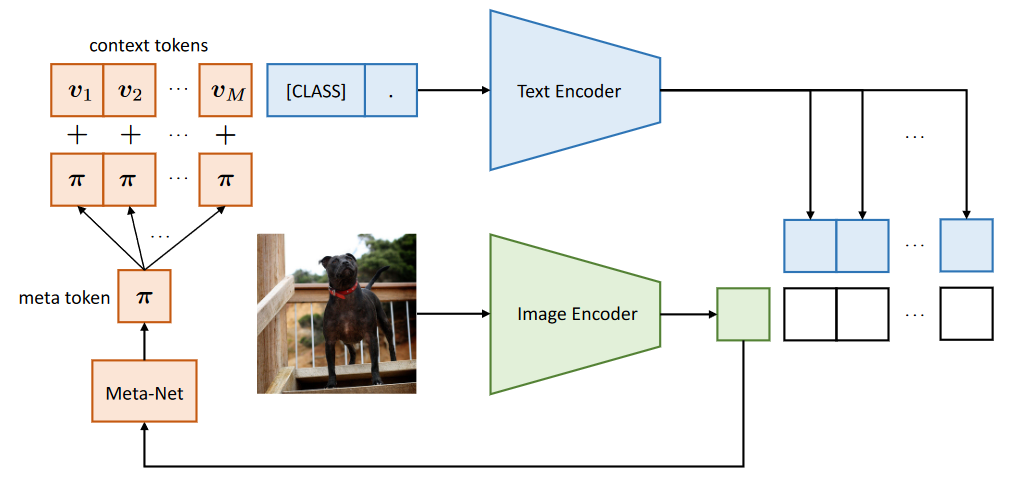
CoCoOp的做法很简单,他在CoOp的基础上,引入了一个轻量的网络Meta-Net(仅仅是Linear-ReLU-Linear),将image Encoder的输出通过Meta-Net得到一个M维的向量,将这M维的向量直接加在CoOp上的每一个prompt token上,通过这种方式做到instance-specific context。这种方式其实就是把每个图片的特征引入了prompt的构造里,所以CoCoOp的第一个Co就是指这种Conditional。
DenseCLIP: Language-Guided Dense Prediction with Context-Aware Prompting
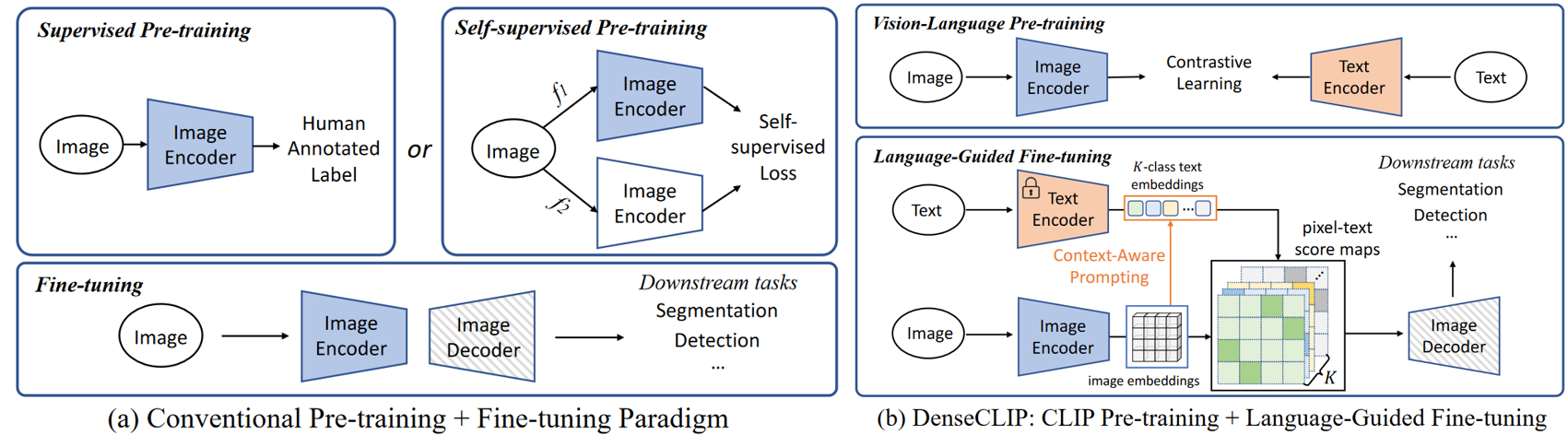
DenseCLIP作者提出一种针对密集任务的新的框架,此框架显式和隐式地利用了CLIP的先验。具体地,作者将原本CLIP中的image-text匹配问题转变为pixel-text匹配问题,并且用匹配中产生的pixel-text score map来指导密集预测模型。通过利用图像中的上下文信息来prompt语言模型可以DenseCLIP更好地利用预训练知识。不同于一般的pretrain+finetune范式,DenseCLIP采用和CoOp及CoCoOp类似的pretrain + language-guide finetune范式。具体地,DenseCLIP采用基于视觉-语言预训练模型CLIP的prompt finetuning方式。
Language-Guided Dense Prediction
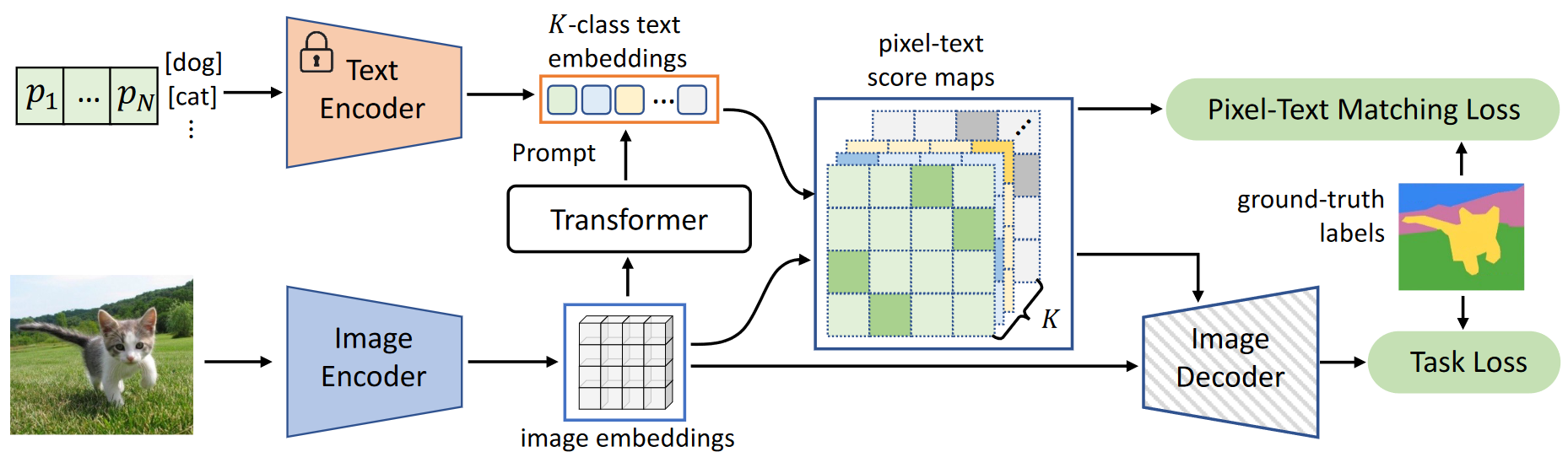
- $\{x_i\}_{i=1}^4$为ResNet的四个block的输出的feature map;
- 对ResNet最后一个block的输出的spatial拉平表示,sptial size: $H_4W_4$ ,number of channels:$C$ ;
- 在CLIP中增加了一个attention pooling layer,首先对$x_4 \in \mathbb{R}^{H_4W_4 \times C}$执行global avg pooling,得到全局feature $\bar{x4} \in \mathbb{R}^{1 \times C}$,其中H4、W4、C是来自主干第4阶段的特征映射的高度、宽度和通道数。
- 接着将[$\bar{x_4}$, $x_4$] 送入多头自注意层(multi-head self-attention layer, MHSA), 得到$[\bar{z}, z] = MHSA[\bar{x_4}, x_4]$,此时$\bar{z} \in \mathbb{R}^{1 \times C}, z \in \mathbb{R}^H_4W_4 \times C$ ; ($z$ 仍然保留了足够的空间信息,因此可以用作特征图。$MHSA$对每个输入元素都是对称的,$z$的行为可能类似于$\bar{z}$,这与语言特征非常一致,可以使用$z$作为文本兼容的特征映射。)
- 使用K个类名称,可以从模板“a photo of a [CLS]”构建文本提示,使用text encoder 提取出text feature $t\in \mathbb{R}^{K \times C}$。这样可以使用vision feature $z$ 和text feature $t$ 计算像素-文本 score map $s$:$s=\hat{z} \hat{t}^\top, s \in \mathbb{R}^{H_4W_4 \times K}$,其中$\hat{z}$和$\hat{t}$是$z$和$t$沿通道维度$ l2 normalized$ 的结果。
Context-Aware Prompting
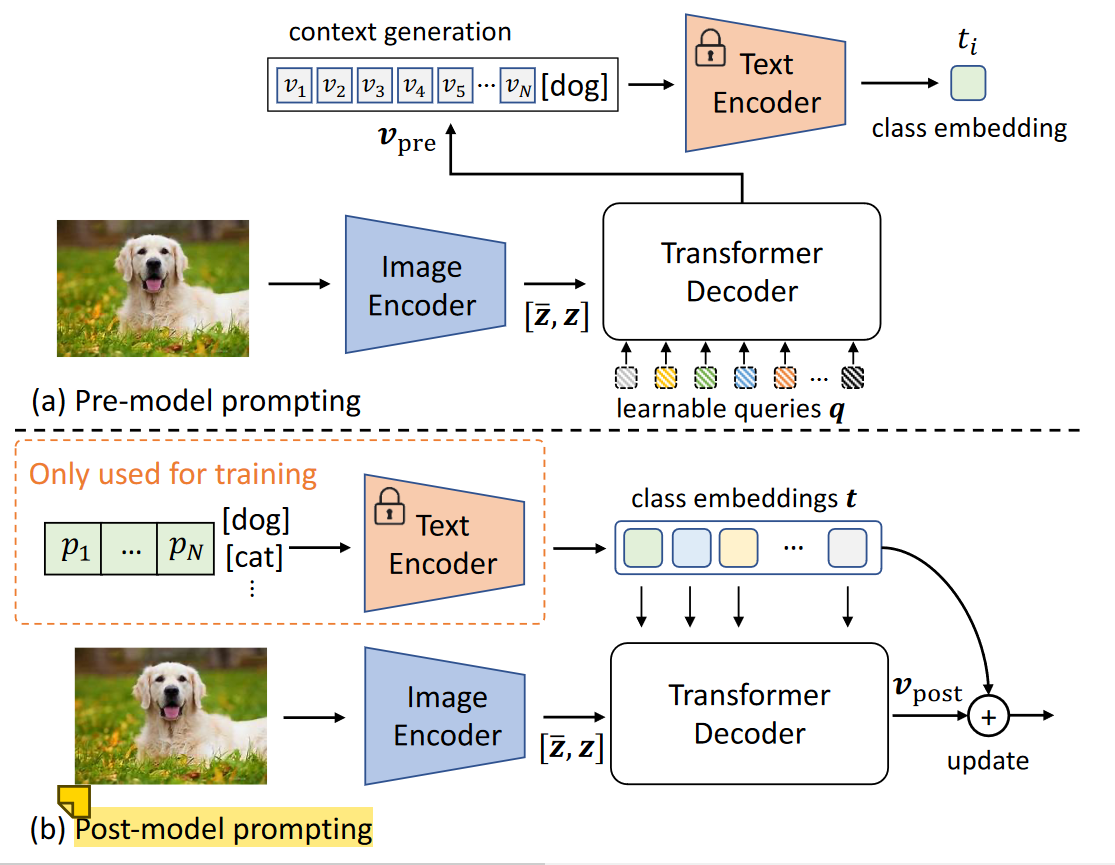
CoOp可以理解为Language-domain prompting,因为CoOp中learnable context仅仅是一个可学的向量,没有包含视觉信息;而DenseCLIP则采用Vision-to-language prompting,也就是在上述learnable context中再引入一些视觉信息(使用视觉信息去 refine text feature)。作者这里介绍了两种refine方式:pre-model prompting和post-model prompting。即:
Pre-model prompting:引入一个可学的query向量 $q\in \mathbb{R}^{N \times C}$(N为text中的context length),将其和特征$[\bar{z}, z]$送入Transformer Decoder 进行 cross-attention来refine视觉上下文:
CoOp中text encoder的输入为$[p,e_k], 1 \leq k \leq K$,DenseCLIP使用$V_{pre}替换$CoOp中的可学习的textual contexts $p$。
Post-model prompting:首先使用CoOp生成文本特征$t\in \mathbb{R}^{K \times C}$,作为Transformer decoder的queies去query vision features$ [\bar{z},z]$ 得到vision context $v_{post} = TransDecoder(t,[\bar{z}, z]) \in \mathbb{R}^{K \times C}$,再拿$v_{post}$去refine text feature t 。最终使用残差连接$t \leftarrow t+\gamma v_{post}$更新text feature,其中$\gamma \in \mathbb{R}^{C}$是可学习的参数。
实证结果表明,pre-model prompting比post-model prompting具有更好的prompting效果。
CPT:Colorful Prompt Tuning for Pre-Training Vision-Language Models
MAPLE: MULTI-MODAL PROMPT LEARNING
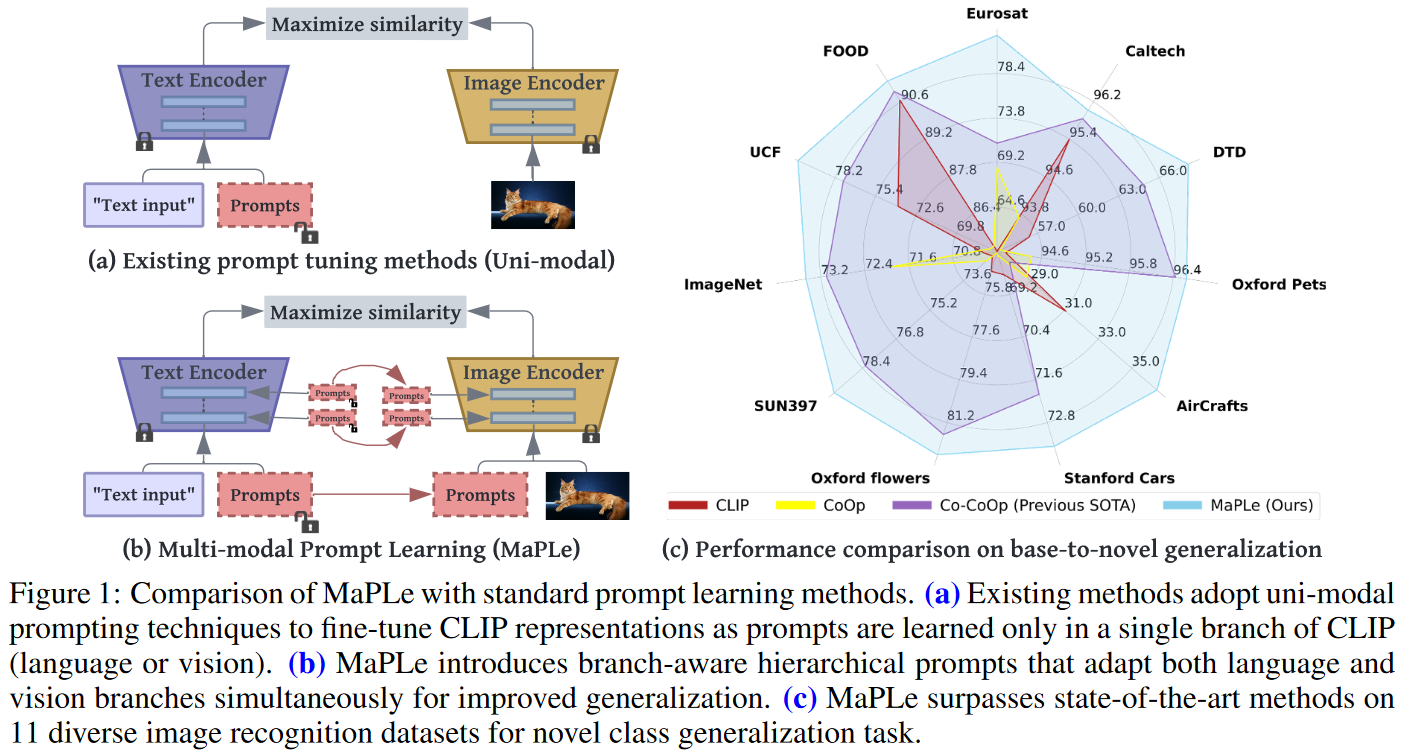
这篇文章的出发点很有新意,一直以来我们做prompt都是在图片或者文本一个模态做prompt,这篇文章觉得只在其中一个模态(分支)做prompt只能达到次优的性能,所以他们提出应该在每一个模态都应该做prompt,示意图如上所示。
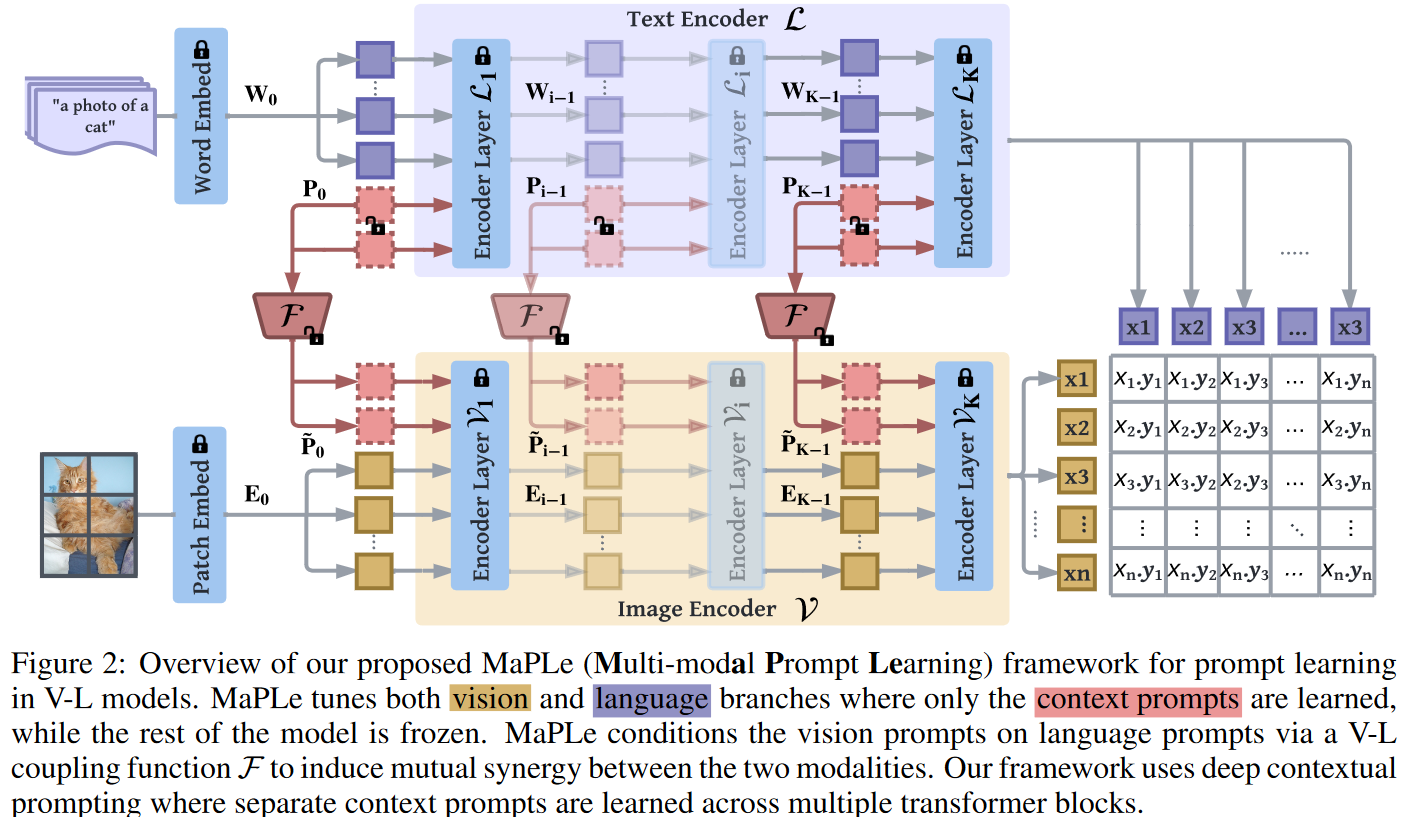
模型架构图如上所示:首先文本端除了文本的输入embedding,会拼接一些文本prompt向量,图像端同样除了图像的embedding输入,也会拼接一些图像prompt向量。这里要注意,这两个prompt向量是有交互的,因为作者认为为了让prompt发挥拉近不同模态距离的作用,不同模态的prompt应该要深层交互。具体交互的做法就是将文本prompt的embedding,通过一个linear层 映射到图像embedding维度,转换成图像prompt向量,但这个交互只会发生在前J层,后面J-K层就不需要交互了,因为作者认为经过前面的交互,后面层的特征已经不是各自独立模态的特征了,自然不需要交互了。
Expanding Language-Image Pretrained Models for General Video Recognition
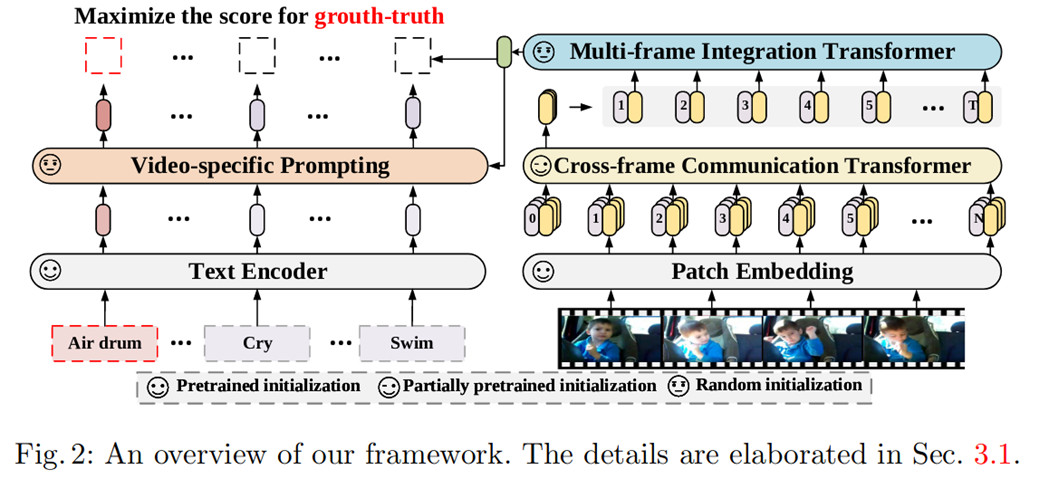
在视频内容理解领域,为节省计算 / 数据开销,视频模型通常 「微调」图像预训练模型。而在图像领域, 最近流行的语言 - 图像预训练模型展现了卓越的泛化性,尤其是零样本迁移能力。那么人们不禁要问:能否有一种视频模型兼顾「微调」 的高效和 「语言 - 图像预训练」的全能?由此微软的研究者提出了将语言 - 图像预训练模型拓展到通用视频识别的方法,在建模时序信息的同时,利用类别标签文本中的语义信息。
本文中,研究者提出了一种简单高效的视频编码器。该编码器由两部分组成,即 Cross-frame Communication Transformer(CCT)和 Multi-frame Integration Transformer(MIT)。为了避免联合时空建模的高计算量,整体上,CCT 采用各帧独立编码的计算方式。
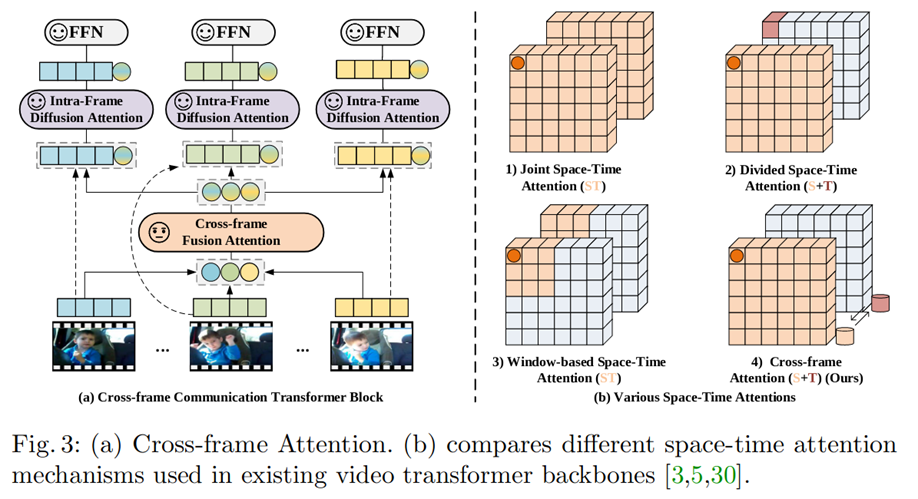
具体地,对每一帧编码时,动态地生成各自的 message token(如图 6(a)中彩色的圆形部分),携带所在帧的信息,再通过 Cross-frame Fusion Attention 交换不同帧的 message token 携带的信息,弥补了时序信息的缺失。具体地,如图 6(a)所示,在 CCT 的每一个 block 中,我们在 cls token 上施加线性变化得到 message token,每帧的 message token 通过 Cross-frame Fusion Attention(CFA)交换信息,
随后,每一帧的 message token 再回归到所属帧。通过 Intra-frame Diffusion Attention,每一帧内的 spatial tokens 在建模空间信息的同时,吸收了来自 message token 的全局时序信息,
利用标签的语义信息:视频自适应的提示学习
针对第二个问题,提示学习(Prompt learning)主张为下游任务设计一种模板,使用该模板可以帮助预训练模型回忆起自己预训练学到的知识。比如, CLIP[4] 手动构造了 80 个模板,CoOp[5]主张构造可学习的模板。
研究者认为,人类在理解一张图片或视频时,自然地会从视觉内容中寻找有判别性的线索。例如有额外的提示信息「在水中」,那么「游泳」和「跑步」会变得更容易区分。但是,获取这样的提示信息是困难的,原因有二:
- 数据中通常只有类别标签,即「跑步」、「游泳」、「拳击」等名称,缺乏必要的上下文描述;
- 同一个类别下的视频共享相同的标签信息,但它们的关键视觉线索可能是不同。
为了缓解上述问题,研究者提出了从视觉表征中学习具有判别性的线索。具体地,他们提出了视频自适应的提示模块,根据视频内容的上下文,自适应地为每个类别生成合适的提示信息。每个视频的自适应提示模块由一个 cross-attention 和一个 FFN 组成。令文本特征当作 query,视频内容的编码当作 key 和 value,允许每个类别的文本从视频的上下文中提取有用的提示信息作为自己的补充。
- 1.对每一帧的class token做线性变换,得到message token,代表这一帧的信息
- 2.在message tokens之间做attention (CFA)
- 3.做完attention的message token重新concat到每一帧中,和patch embeddings做帧内的attention (IFA)